最近sam3出来了,输入个关键词就能识别图片中的目标物,这实在是太牛了。SAM(Segment Anything Model)是由Meta公司于2023年4月发布的人工智能通用模型,专注于图像分割任务。目前开源的有sam、sam2。sam3是刚刚开源,但是我已经被其强大的功能折服。
1、安装部署
| |
| NVIDIA GeForce RTX 4090 D |
| |
接下来创建环境、下载代码,我这边是使用conda来管理环境的。后台回复“conda”可拿到win、Linux的conda安装包git clone
conda create -n sam3 python=3.12
conda activate sam3
2、安装环境
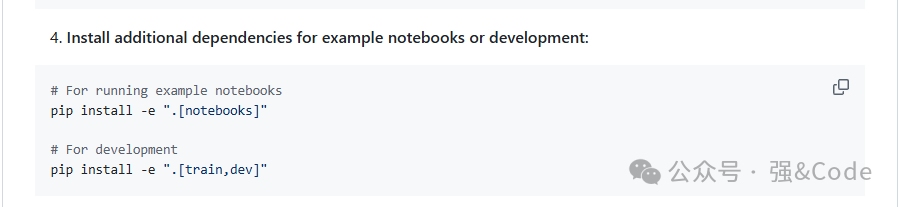
这个安装过程中竟然没有出现报错,有点出乎我的意料 。如果有其他的需求的话,比方说使用notebook或者训练需求的,GitHub上面也说明了其他的安装方式。
。如果有其他的需求的话,比方说使用notebook或者训练需求的,GitHub上面也说明了其他的安装方式。
3、安装torch
根据自己cuda版本安装pytorch
pip install torch==2.7.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
4、下载模型
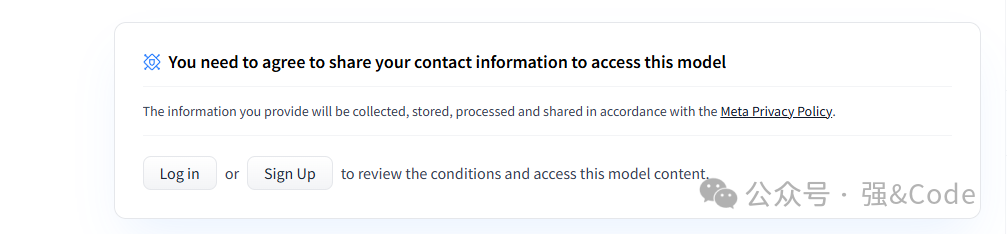
代码中默认是从huggingface下载模型,但是在huggingface上面下载还需要申请。
没关系,还有其他的下载方式。
推荐从modelscope下载模型,下载好后放到项目代码中。
下载地址:https://modelscope.cn/models/facebook/sam3
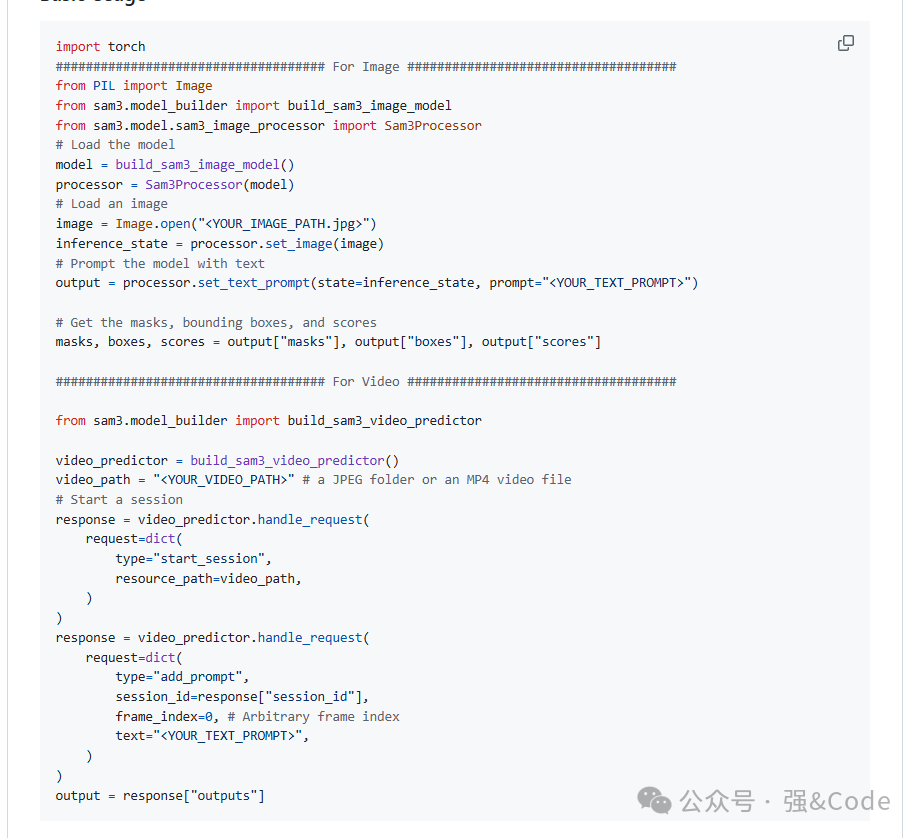
5、测试
GitHub上面提供了基础的示例,我这边只测试了图片的。测试过程中发现有少安装的包,这个的话,缺少哪个安装哪个就可以了。我还基于sam2的环境来测试下sam3的程序,发现也是缺少一些安装包,这个也是缺少哪个包装哪个就可以了,最后在sam2的环境上面完美将sam3的图像识别程序跑了起来。
修改自己的图片路径,更换自己要识别的目标物词,注意不识别中文。看着不错,加大点难度,识别一下小目标物。“car emblem”车标、“license plate” 车牌 虽然有漏的可能确实不太清晰,不好识别,但是没有识别错误的。再识别下图片中容易识别错误的。“street light” 路灯,这个里面有相似物,看下识别效果。这就是我测试sam3的整个过程,大家有想测试的欢迎安装体验。
打赏

支付宝微信扫一扫,打赏作者吧~
本文链接:https://kinber.cn/post/6105.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: 
 。
。