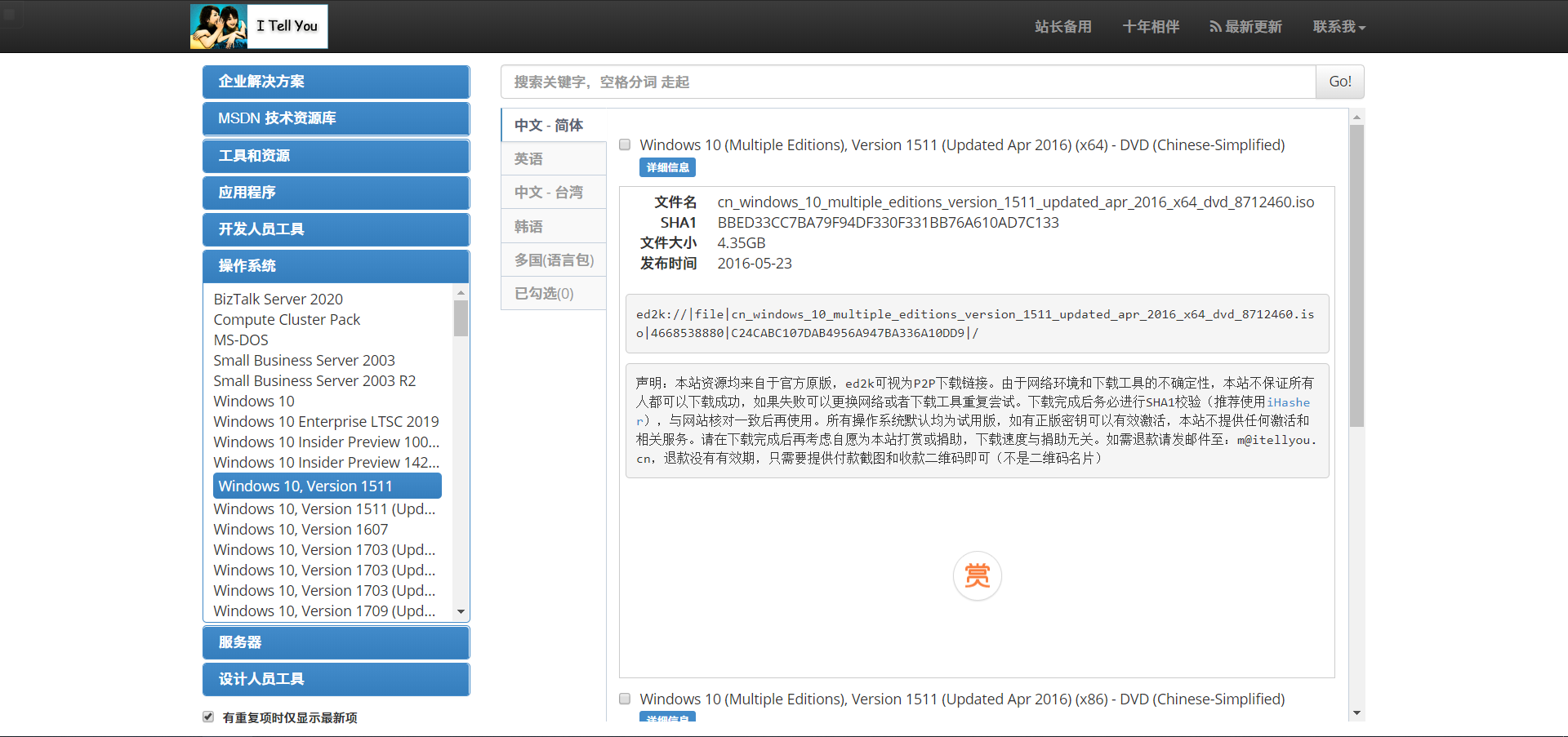
今日,msdn的新网站开放注册,然后体验了一波,发现要强制观看30S的广告才可以下载,因此就想提前把资源爬取下来以便后用。
先来看下成果:
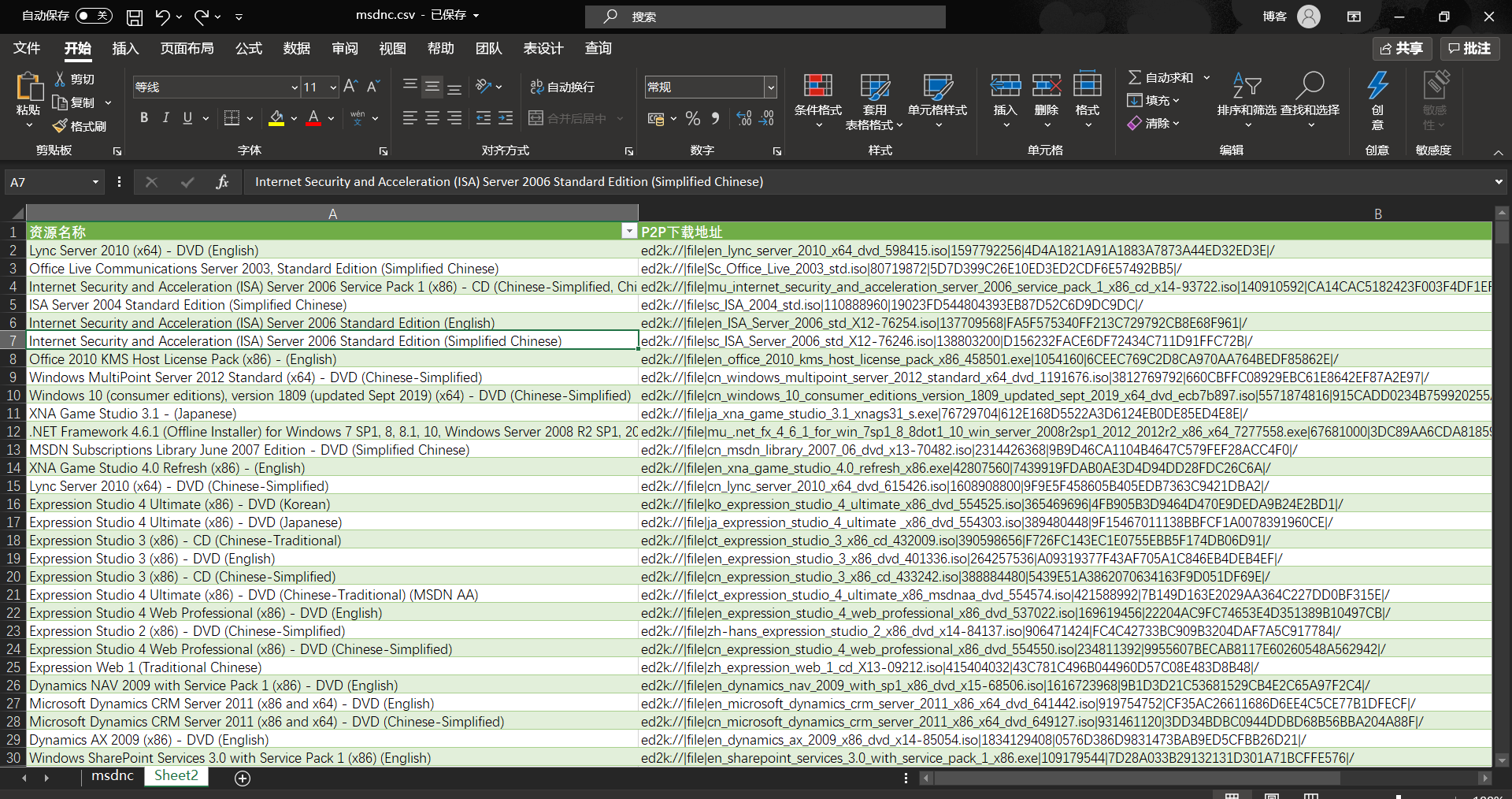
1,网站分析
1.1通过直接爬取:https://msdn.itellyou.cn/,可以获得8个ID,对应着侧边栏的八个分类

1.2没展开一个分类,会发送一个POST请求
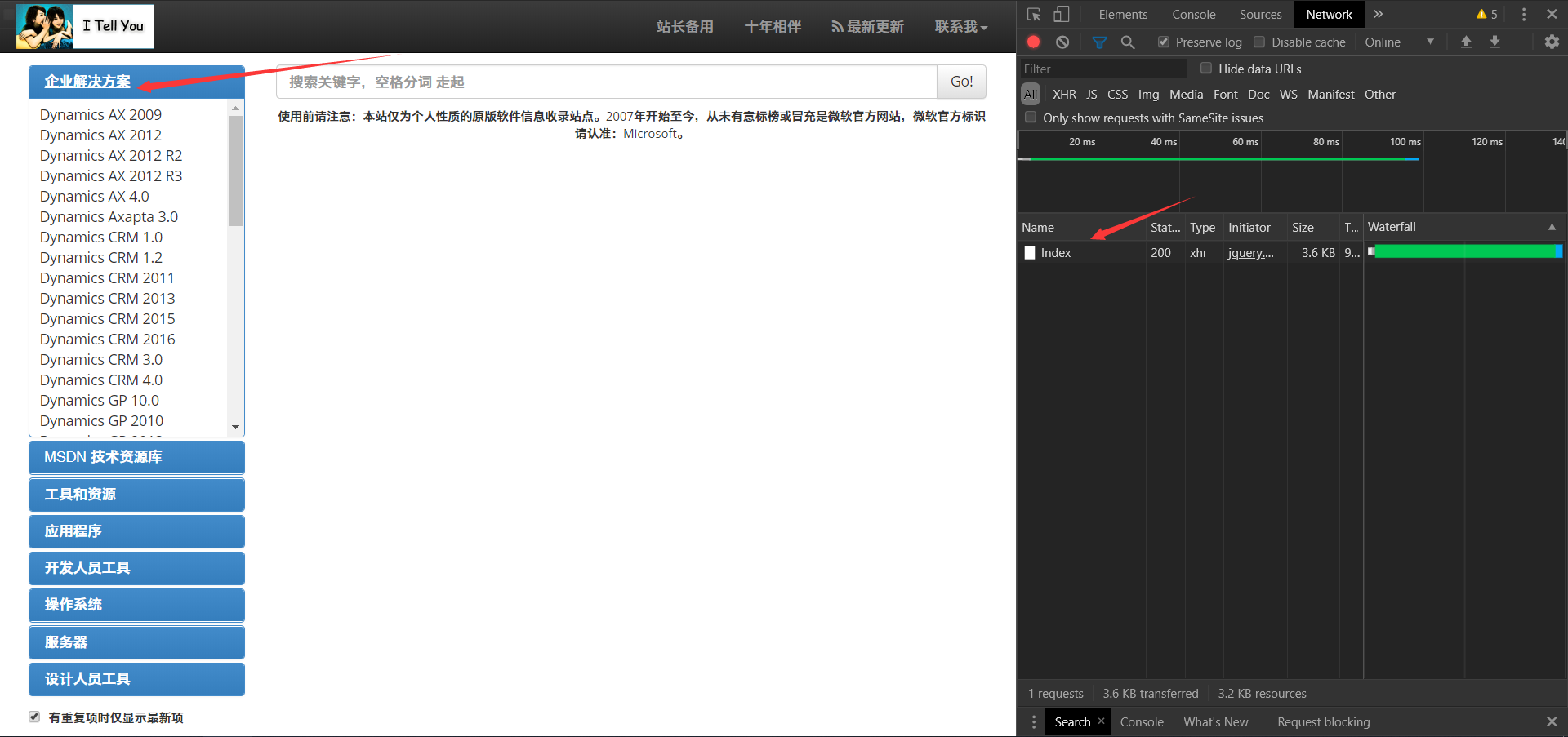
传递的就是之前获取的8个ID之一
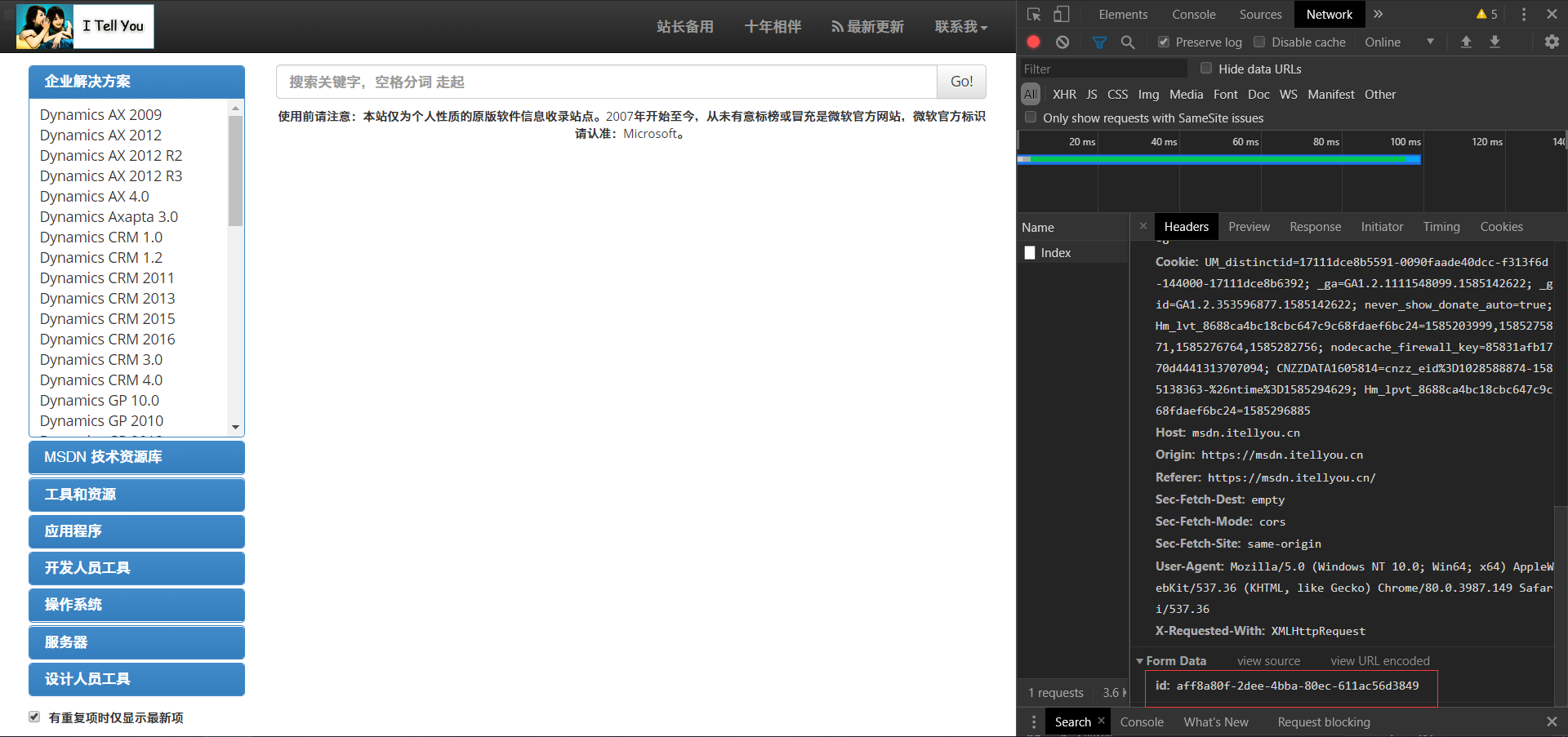
1.3查看这个请求的返回值,可以看到又获得一个ID,以及对应的资源名称。
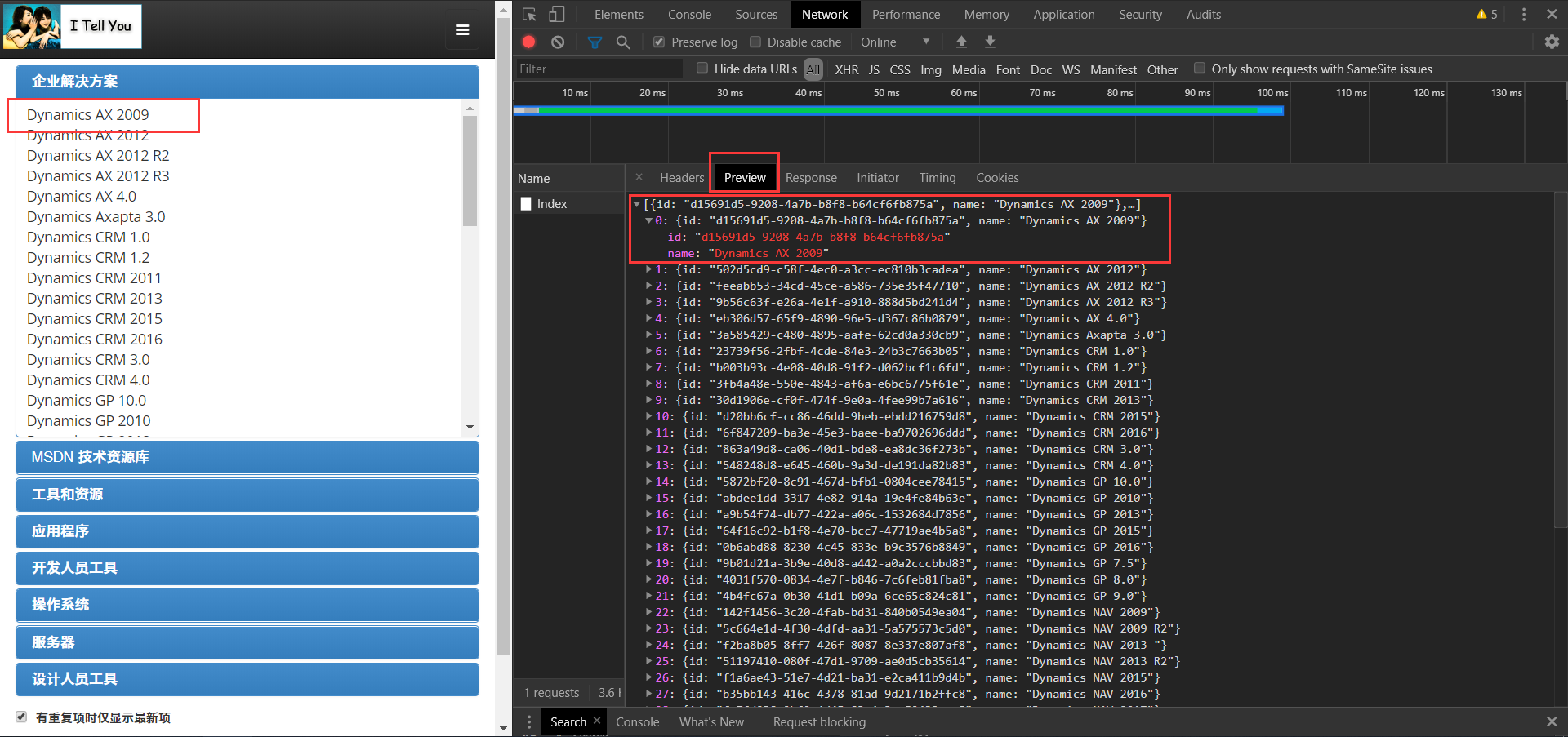
1.4点击,展开一个资源可以发现,又多了两个POST请求
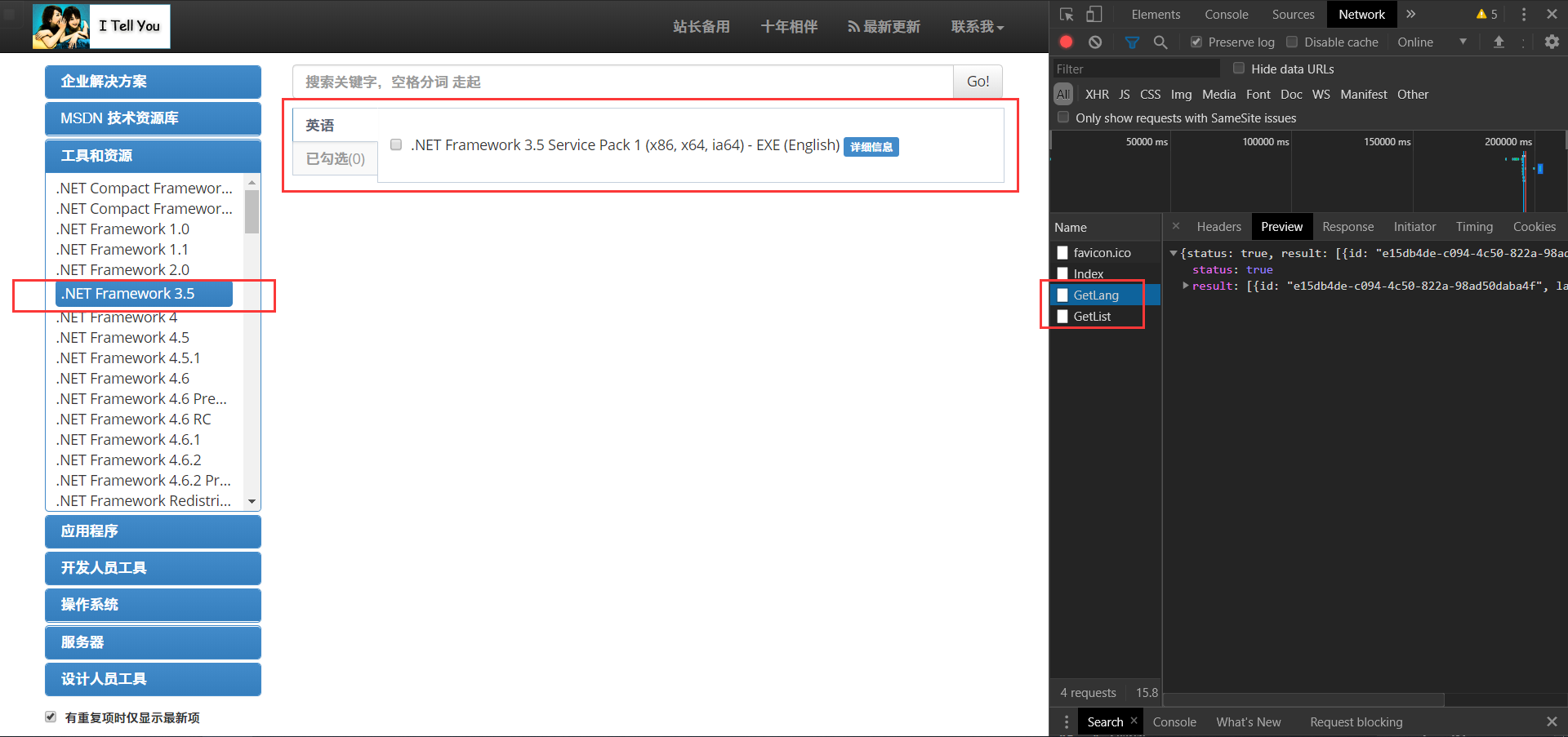
1.4.1第一个GETLang,经分析大概意思就是,获取资源的语言,然后这个请求也发送了一个ID,然后在返回值中又获得一个ID,这就是后文中的lang值
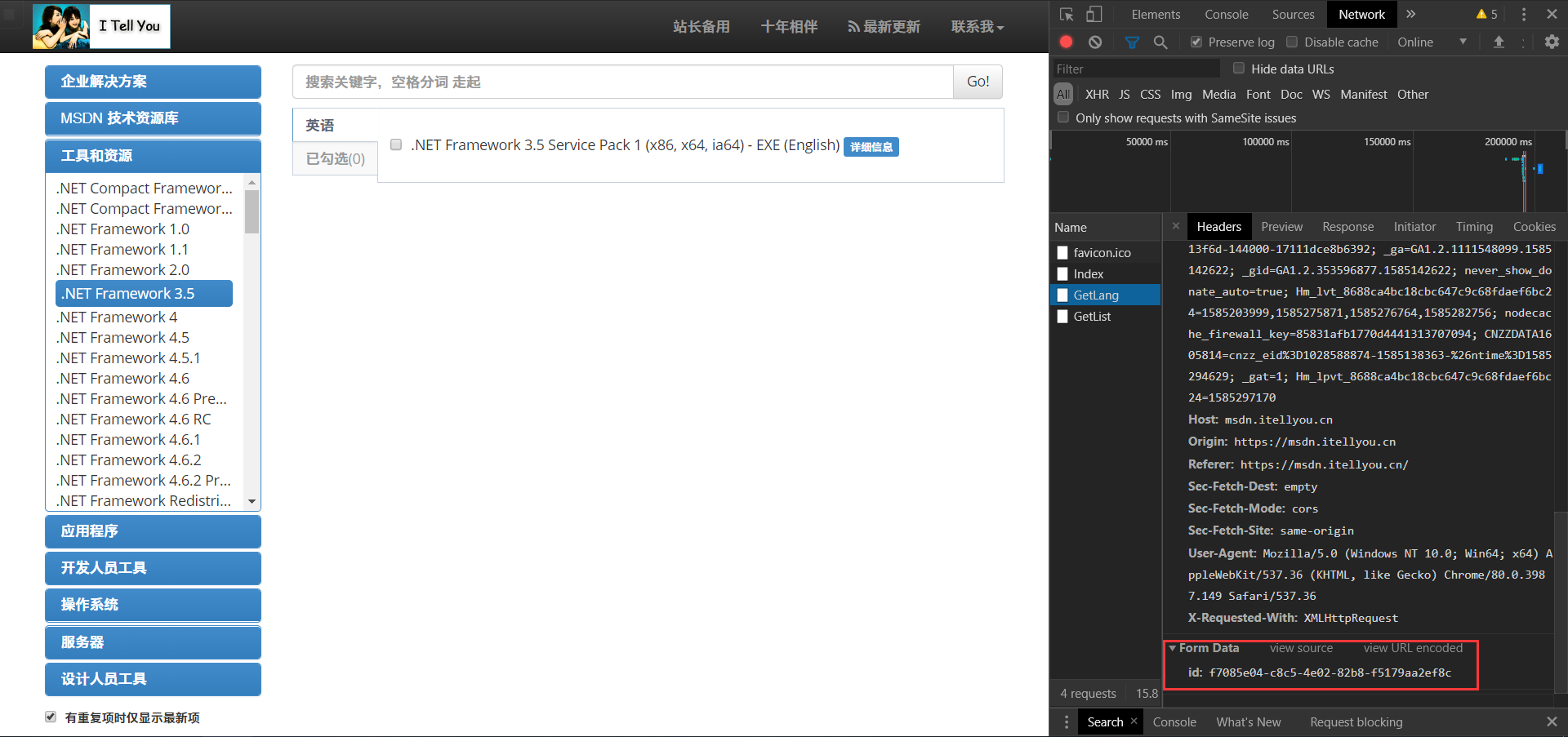
1.4.2第二个GetList,这个传递了三个参数:
(1)ID:经对比可发现这个ID就是我们之前一直在用的ID。
(2)lang,我后来才发现是language的缩写,就是语言的意思,我们从第一个GetLang的返回值可以获取,这个lang值。
(3)filter,翻译成中文就是过滤器的意思,对应图片坐下角的红色框框内是否勾选。
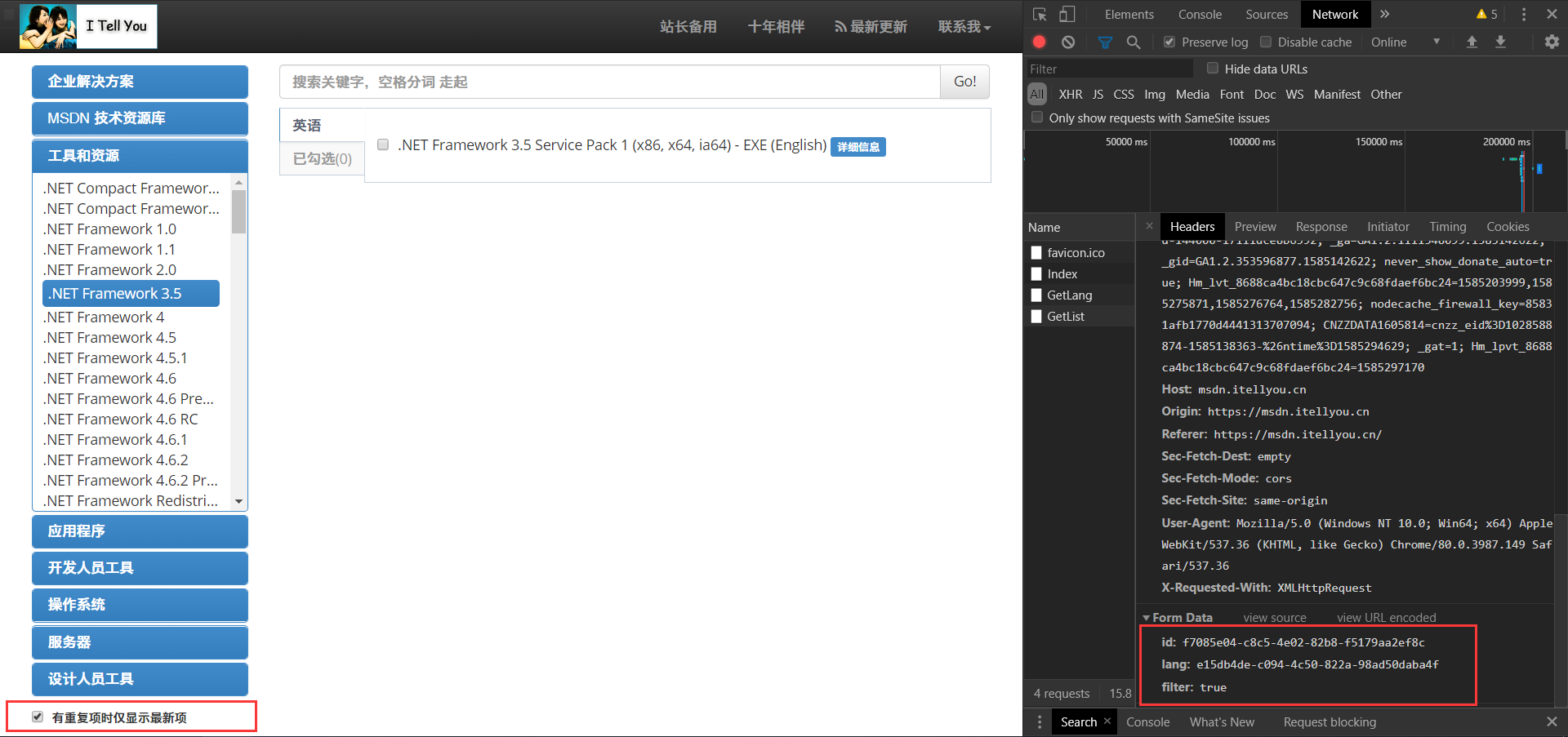
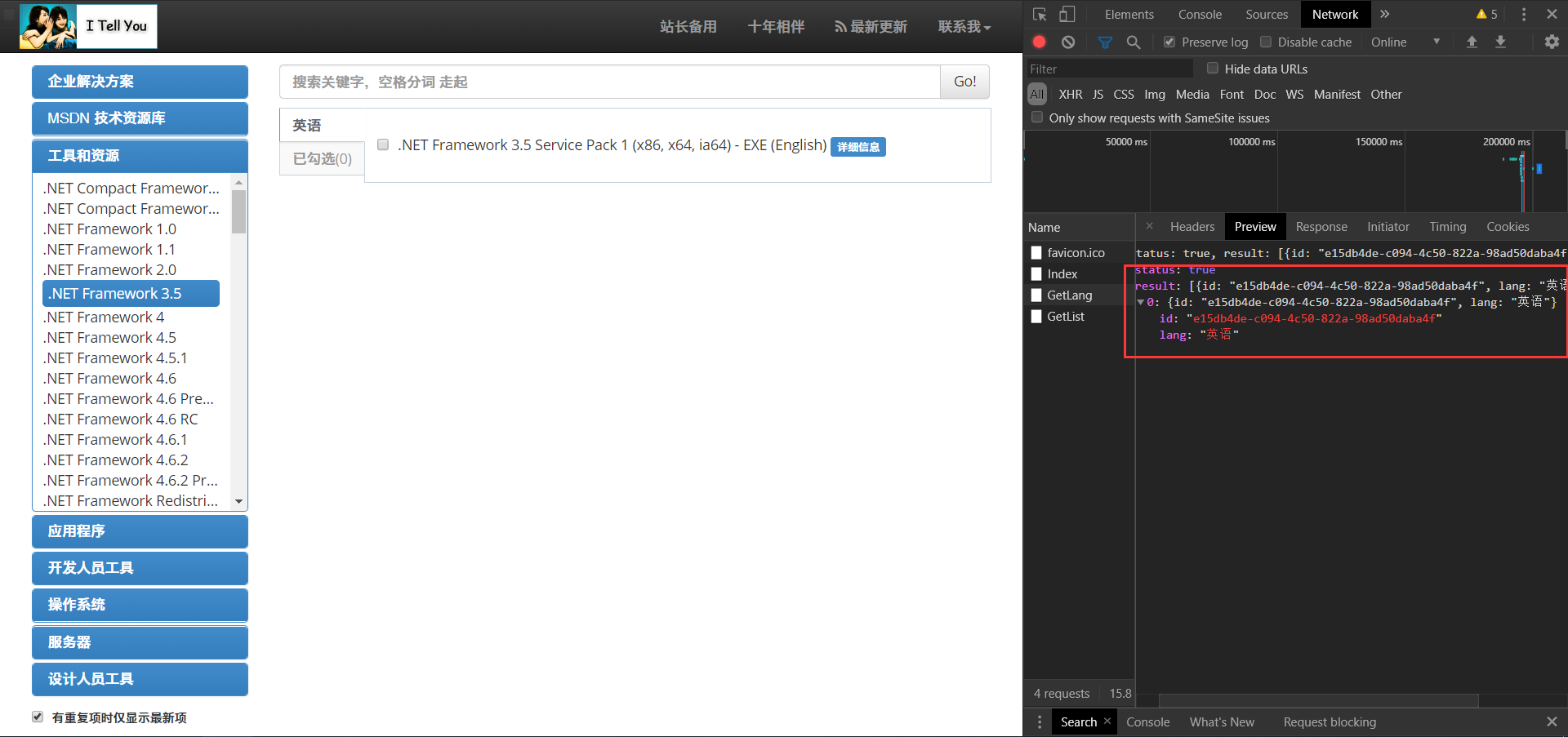
1.4.3到这里就以及在返回值中获得了下载地址了:
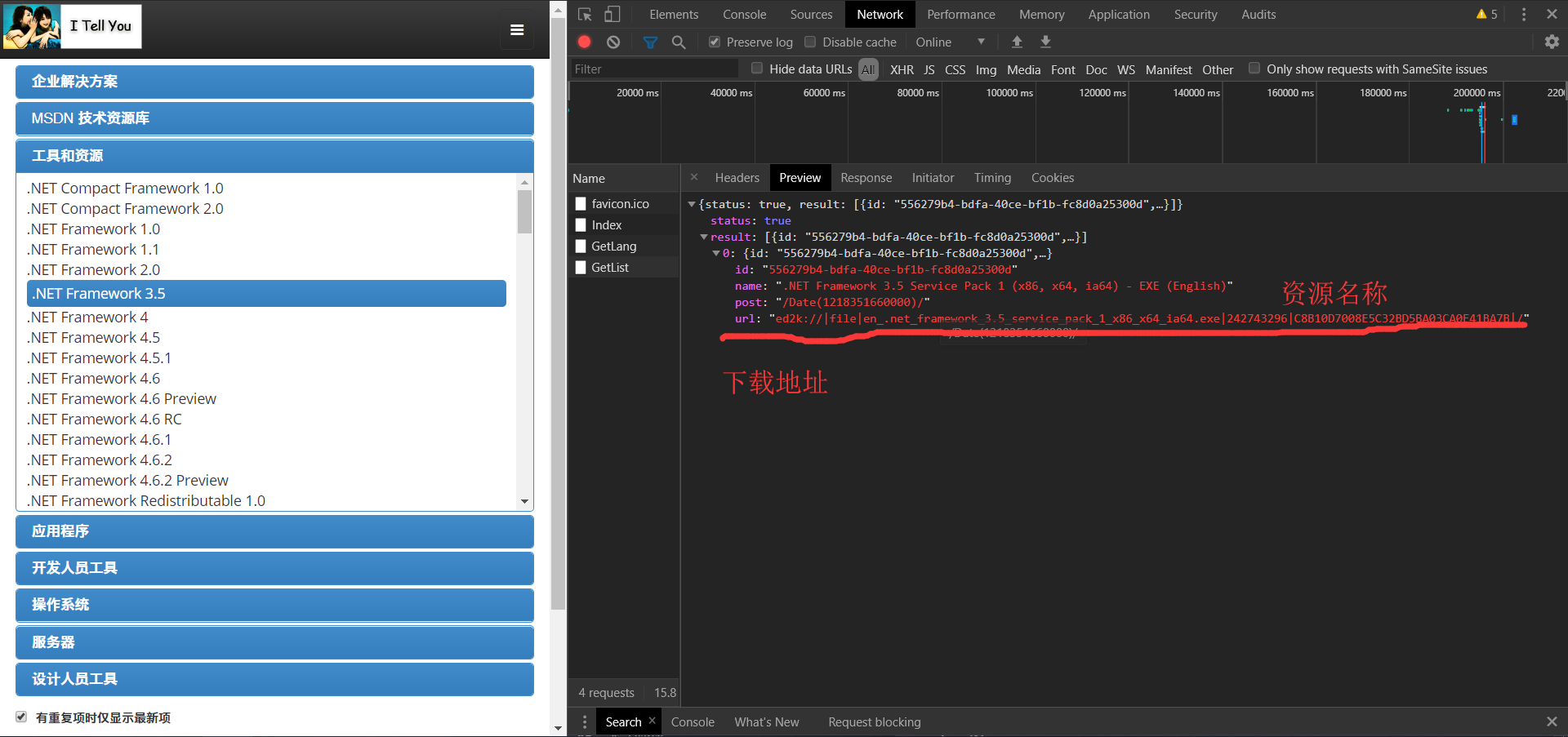
综上就是分析过程。然后就开始敲代码了
2,为了追求速度,选择了Scrapy框架。然后代码自己看吧。
爬虫.py:
# -*- coding: utf-8 -*-
import json
import scrapy
from msdn.items import MsdnItem
class MsdndownSpider(scrapy.Spider):
name = 'msdndown'
allowed_domains = ['msdn.itellyou.cn']
start_urls = ['http://msdn.itellyou.cn/']
def parse(self, response):
self.index = [i for i in response.xpath('//h4[@class="panel-title"]/a/@data-menuid').extract()]
# self.index_title = [i for i in response.xpath('//h4[@class="panel-title"]/a/text()').extract()]
url = 'https://msdn.itellyou.cn/Category/Index'
for i in self.index:
yield scrapy.FormRequest(url=url, formdata={'id': i}, dont_filter=True,
callback=self.Get_Lang, meta={'id': i})
def Get_Lang(self, response):
id_info = json.loads(response.text)
url = 'https://msdn.itellyou.cn/Category/GetLang'
for i in id_info: # 遍历软件列表
lang = i['id'] # 软件ID
title = i['name'] # 软件名
# 进行下一次爬取,根据lang(语言)id获取软件语言ID列表
yield scrapy.FormRequest(url=url, formdata={'id': lang}, dont_filter=True, callback=self.Get_List,
meta={'id': lang, 'title': title})
def Get_List(self, response):
lang = json.loads(response.text)['result']
id = response.meta['id']
title = response.meta['title']
url = 'https://msdn.itellyou.cn/Category/GetList'
# 如果语言为空则跳过,否则进行下次爬取下载地址
if len(lang) != 0:
# 遍历语言列表ID
for i in lang:
data = {
'id': id,
'lang': i['id'],
'filter': 'true'
}
yield scrapy.FormRequest(url=url, formdata=data, dont_filter=True, callback=self.Get_Down,
meta={'name': title, 'lang': i['lang']})
else:
pass
def Get_Down(self, response):
response_json = json.loads(response.text)['result']
item = MsdnItem()
for i in response_json:
item['name'] = i['name']
item['url'] = i['url']
print(i['name'] + "--------------" + i['url']) # 测试输出,为了运行时不太无聊
return item
items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MsdnItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
url = scrapy.Field()
settings.py:
# -*- coding: utf-8 -*-
# Scrapy settings for msdn project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'msdn'
SPIDER_MODULES = ['msdn.spiders']
NEWSPIDER_MODULE = 'msdn.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'msdn (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.1
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'msdn.middlewares.MsdnSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'msdn.middlewares.MsdnDownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'msdn.pipelines.MsdnPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
pipelines.py:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class MsdnPipeline(object):
def __init__(self):
self.file = open('msdnc.csv', 'a+', encoding='utf8')
def process_item(self, item, spider):
title = item['name']
url = item['url']
self.file.write(title + '*' + url + '\n')
def down_item(self, item, spider):
self.file.close()
main.py(启动文件):
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'msdndown'])

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://kinber.cn/post/2293.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: 