我们知道zabbix在监控界占有不可撼动的地位,功能强大。但是对容器监控显得力不从心。为解决监控容器的问题,引入了prometheus技术。prometheus号称是下一代监控。接下来的文章打算围绕prometheus做一个系列的介绍,顺便帮自己理清知识点。
一、简介
prometheus是由谷歌研发的一款开源的监控软件,目前已经被云计算本地基金会托管,是继k8s托管的第二个项目。
二、优势
易于管理
轻易获取服务内部状态
高效灵活的查询语句
支持本地和远程存储
采用http协议,默认pull模式拉取数据,也可以通过中间网关push数据
支持自动发现
可扩展
易集成
三、prometheus运行流程
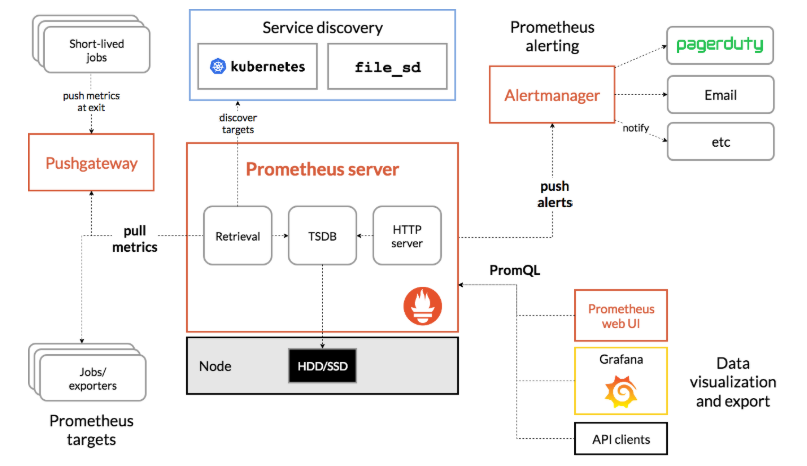
prometheus根据配置定时去拉取各个节点的数据,默认使用的拉取方式是pull,也可以使用pushgateway提供的push方式获取各个监控节点的数据。将获取到的数据存入TSDB,一款时序型数据库。此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。它的报警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和发送报警的一个组件。prometheus原生的图标功能过于简单,可将prometheus数据接入grafana,由grafana进行统一管理。
四、监控的目的
google指出,监控分为白盒监控和黑盒监控之分。
白盒监控:通过监控内部的运行状态及指标判断可能会发生的问题,从而做出预判或对其进行优化。
黑盒监控:监控系统或服务,在发生异常时做出相应措施。
监控的目的如下:
1、根据历史监控数据,对为了做出预测
2、发生异常时,即使报警,或做出相应措施
3、根据监控报警及时定位问题根源
4、通过可视化图表展示,便于直观获取信息
五、常用概念
prometheus采集到的监控数据均以metric(指标)形式保存在时序数据库中(TSDB)
每一条时间序列由 metric 和 labels 组成,每条时间序列按照时间的先后顺序存储它的样本值。
默认情况下各监控client向外暴露一个HTTP服务,prometheus会通过pull方式获取client的数据,数据格式如下:
1 2 3 4 5 6 | # HELP node_cpu Seconds the cpus spent in each mode.# TYPE node_cpu counternode_cpu{cpu="cpu0",mode="idle"} 362812.7890625# HELP node_load1 1m load average.# TYPE node_load1 gaugenode_load1 3.0703125 |
以#开头的表示注释信息,解释了每一个指标的监控目的和类型
node_cpu表示监控指标的名称
{}内的内容是标签,以键值对的方式记录
数字是这个指标监控的数据
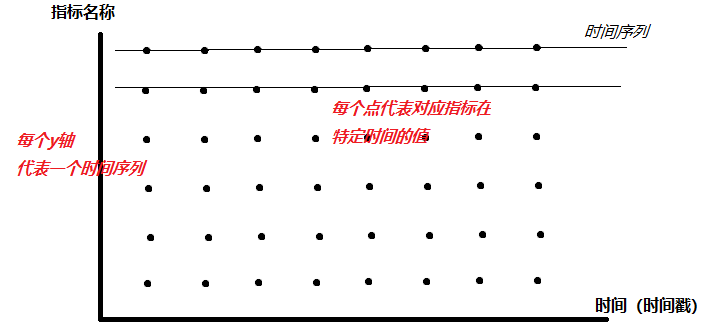
下图横坐标代表的是时间(时间戳的方式记录在TSDB中),纵坐标代表了各种不同的指标名称,坐标系中的黑点代表了各个指标在不同时间下的值。
每一个横线 就是时间序列
每个黑点就是样本(prometheus将样本以时间序列的方式保存在内存中,然后定时保存到硬盘上)
指标(metric)的格式如下:
1 | <metric name>{<label name>=<label value>, ...} |
指标名称反映的是监控了什么。
标签反映的是样本的维度,可以理解成指标的细化。比如:
1 | api_http_requests_total{method="POST", handler="/messages"} |
指标是“api_http_requests_total”,含义是通过api请求的http总数。
标签“method="POST"” "handler="/messages""代表了这些http请求中 POST 请求 并且 handler是/messages的数量
上述指标等同于:
1 | {__name__="api_http_requests_total",method="POST", handler="/messages"} |
指标有四种类型
1、Counter 只增不减 计数器
2、Gauge 可增可减 仪表盘
3、Histogram 直方图
4、Summary 摘要型

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://kinber.cn/post/1617.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: 
