RAG-Anything
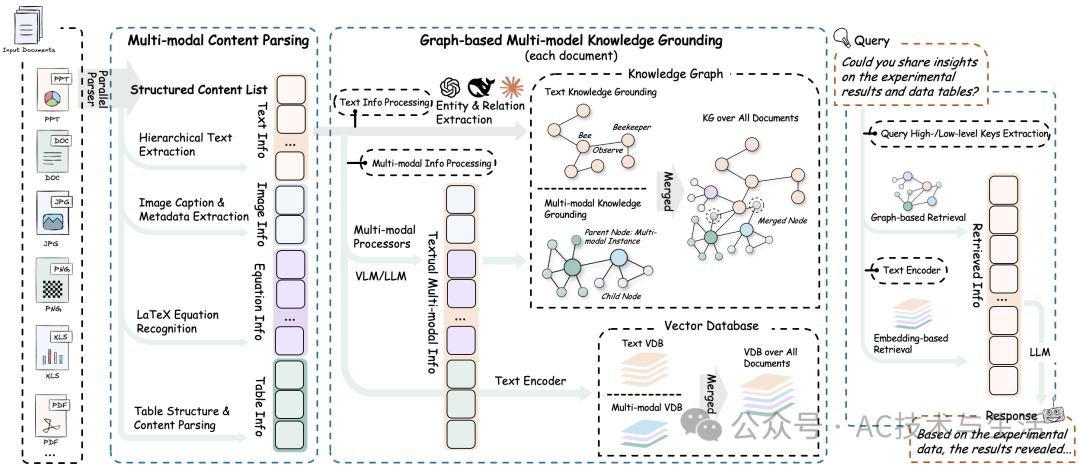
在学术研究、技术报告、金融分析、企业知识管理等领域,我们经常需要处理包含 文本、图片、表格、公式 等多模态内容的文档。传统的RAG(检索增强生成,Retrieval-Augmented Generation)系统多以文本为中心,对这些复杂元素往往力不从心。 RAG-Anything 正是为了解决这一现实痛点而诞生:它是一套 All-in-One 多模态文档处理与RAG系统,基于 LightRAG 构建,能够无缝处理文本、图像、表格、数学表达式等多种信息形式,提供真正的一站式检索与生成体验。 在信息爆炸的今天,我们所面对的文档几乎不再是单一的文字,而是 图文交错、多重结构的复杂文档。传统的纯文本RAG无法保留表格中的数值关系,也无法解读公式背后的语义,更无法解析图像里的核心信息。 RAG-Anything 的优势在于: 从文档解析、内容分类,到知识图谱构建、智能检索,全流程覆盖。 兼容 PDF、Office文档、图片、文本文件 等主流格式。 不仅保存文本,还能把图像、表格、公式转化为图谱节点,进行实体关系推理。 结合 向量搜索 + 图谱遍历,实现语义 + 结构化的智能搜索。 RAG-Anything 的核心管道可概括为以下 5 个阶段: 这种架构保证了复杂文档的高效理解与智能问答。 ? 注意:Office 文档处理依赖 LibreOffice,需额外安装。 这些功能使得科研人员能直接将论文中的图表、公式与上下文知识库结合,得到深度解析。 除了让系统自己解析文档外,RAG-Anything 还支持 直接注入自定义解析结果,例如从外部OCR工具获得的内容: RAG-Anything 提供灵活的配置参数: 这些配置使其能在 快速场景 与 深度研究 间灵活切换。 除了 RAG-Anything,HKUDS 团队还推出了多款 RAG 相关框架: 这三款项目形成了一个完整的 RAG生态圈: 通过 RAG-Anything,我们终于能 在同一个框架中流畅处理文字、表格、图片、公式,真正实现跨模态知识交互。这意味着未来研究人员无需耗费大量时间在格式转换和工具切换上,而是能专注于 知识本身的价值发现。“
? 为什么选择 RAG-Anything?
? 核心功能解析
1. 端到端多模态处理
2. 多格式支持
3. 智能分析器
4. 跨模态知识图谱
5. 多模式检索
?️ 工作原理与架构
? 快速上手
安装方式
pip install raganything
pip install 'raganything[all]' # 开启所有可选特性git clone https://github.com/HKUDS/RAG-Anything.git
cd RAG-Anything
uv sync --all-extras基本用例:完整文档处理与问答
from raganything import RAGAnything, RAGAnythingConfig
config = RAGAnythingConfig(
working_dir="./rag_storage",
parser="mineru", # 支持 mineru 或 docling
enable_image_processing=True,
enable_table_processing=True,
enable_equation_processing=True,
)
rag = RAGAnything(config=config)
# 扫描并处理文档
await rag.process_document_complete(
file_path="research_paper.pdf",
output_dir="./output"
)
# 发起查询(可选择纯文本或多模态模式)
result = await rag.aquery("请解释文中公式的研究意义", mode="hybrid")
print(result)多模态查询场景示例
vlm_result = await rag.aquery("分析文中的图表趋势", mode="hybrid", vlm_enhanced=True)equation_result = await rag.aquery_with_multimodal(
"请解释该概率公式",
multimodal_content=[{"type": "equation", "latex": "P(d|q) = ..."}],
mode="hybrid"
)table_result = await rag.aquery_with_multimodal(
"对比最新结果与表格中的基准结果",
multimodal_content=[{"type": "table", "table_data": "Method,Accuracy..."}],
mode="hybrid"
)?️ 高级功能:直接插入解析内容
content_list = [
{"type": "text", "text": "这是研究论文的引言部分"},
{"type": "image", "img_path": "/path/figure1.jpg", "image_caption": ["图1:模型架构"]},
{"type": "table", "table_body": "| 方法 | 准确率 |\n|---|---|\n| 我们的方法 | 95.2% |"},
]
await rag.insert_content_list(content_list, file_path="custom_paper.pdf")? 典型应用场景
? 系统配置与优化
mineru(更适合科研PDF)或 docling(更适合Office文档)。? 同类优质项目推荐

? 参考地址:
• https://github.com/HKUDS/RAG-Anything

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://kinber.cn/post/5692.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: 