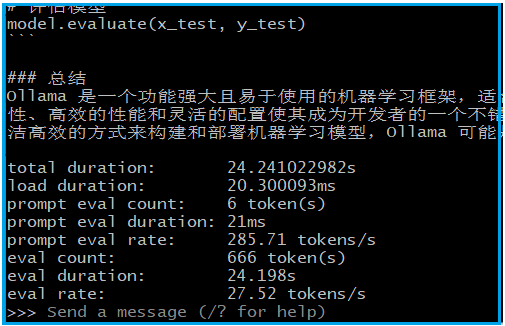
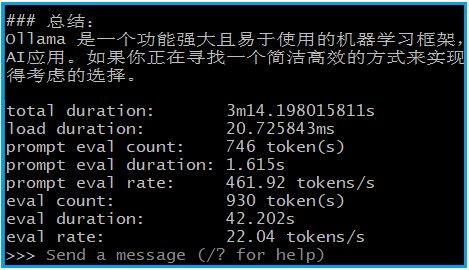
$ollama run deepseek-r1:32b --verbose >>> 介绍一下ollama
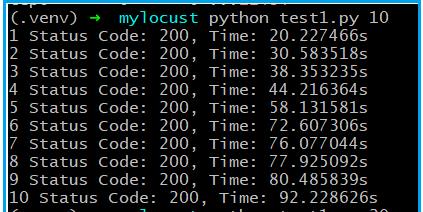
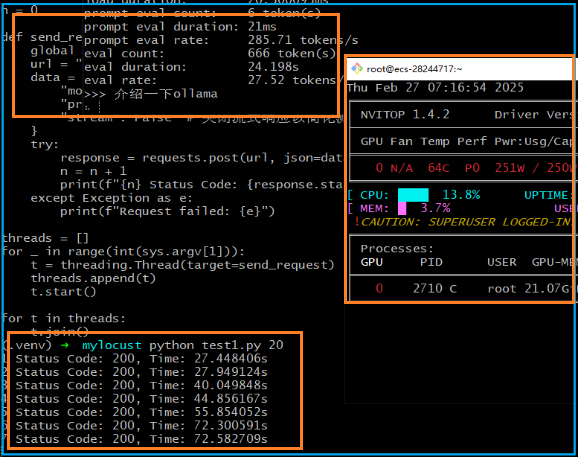
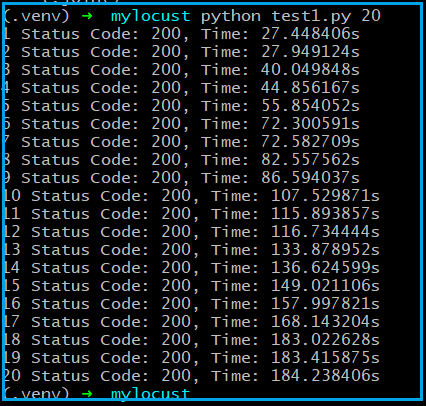
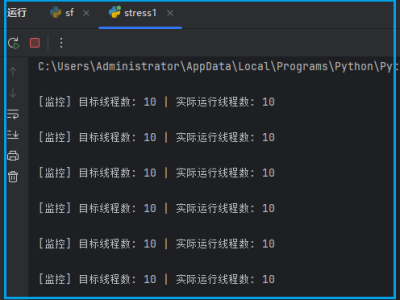
性能测试代码如下:
import requestsimport threadingimport sysn = 0def send_request():
global n
url = "http://127.0.0.1:11434/api/generate"
data = {
"model": "deepseek-r1:32b",
"prompt": "介绍一下ollama",
"stream": False # 关闭流式响应
}
try:
response = requests.post(url, json=data, timeout=None)
n = n + 1
print(f"{n} Status Code: {response.status_code}, Time: {response.elapsed.total_seconds()}s", flush=False)except Exception as e:
print(f"Request failed: {e}")
threads = []for _ in range(int(sys.argv[1])):
t = threading.Thread(target=send_request)
threads.append(t)
t.start()for t in threads:
t.join()

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://kinber.cn/post/4982.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: