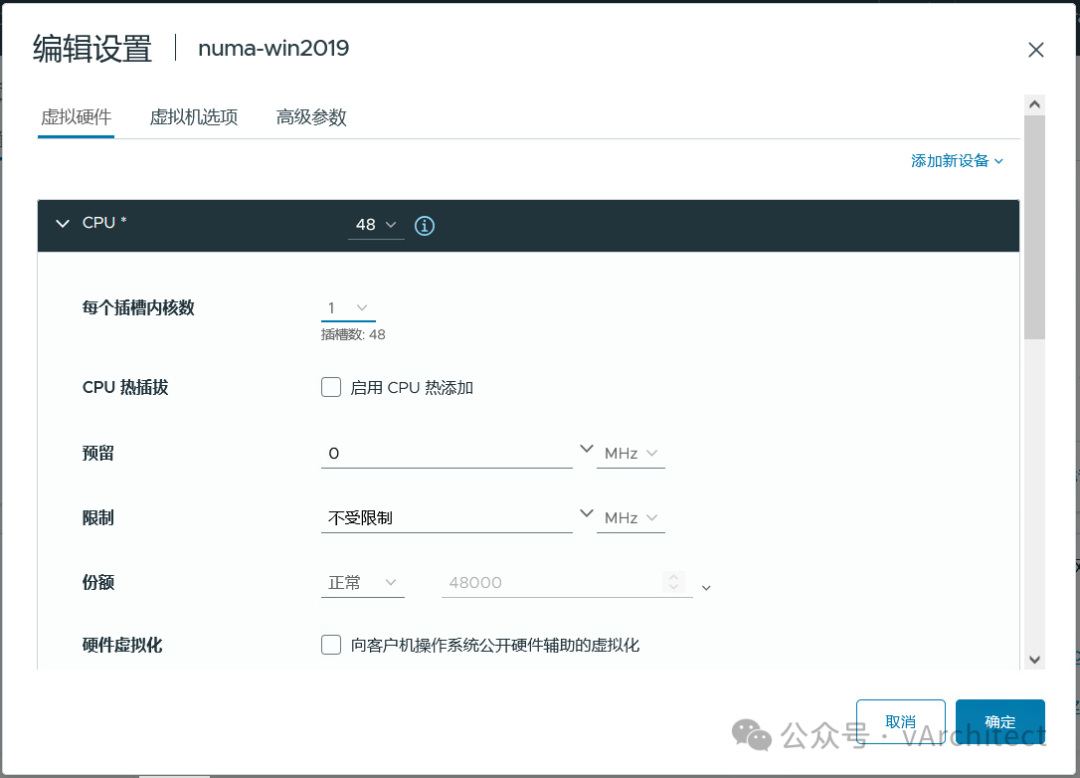
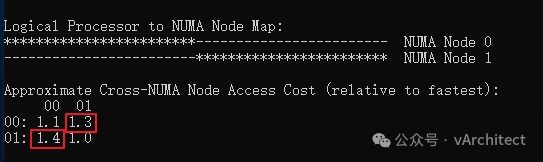
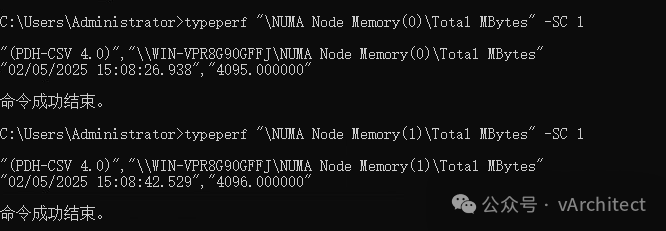
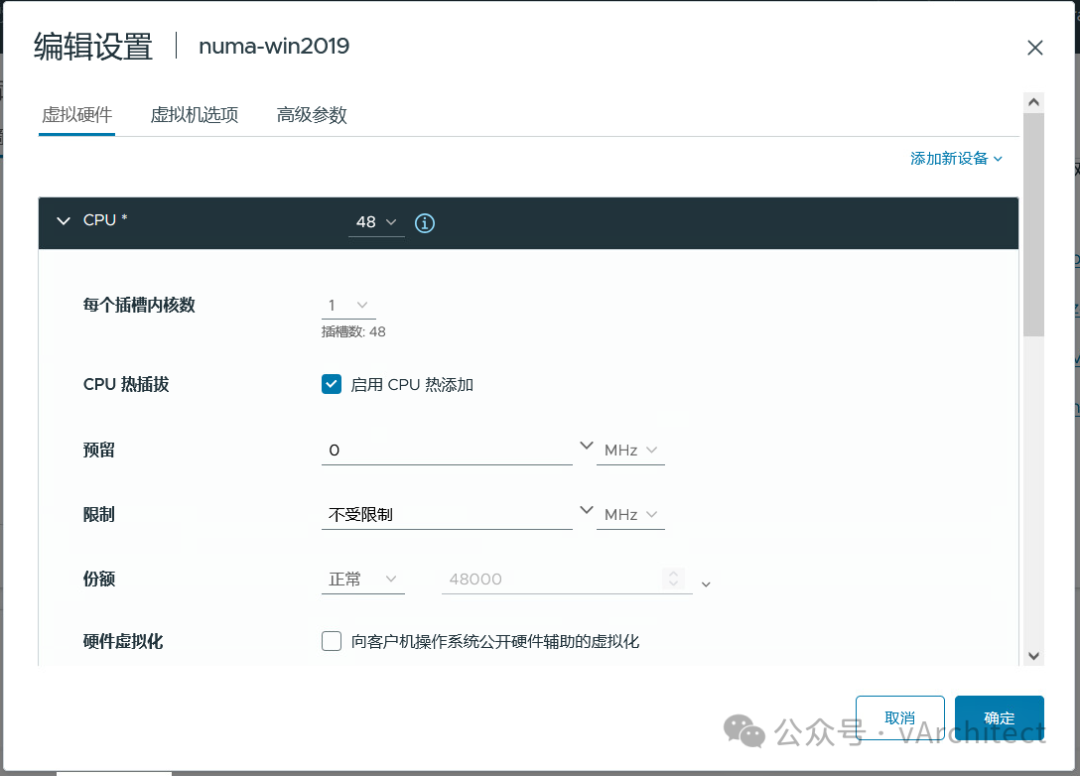
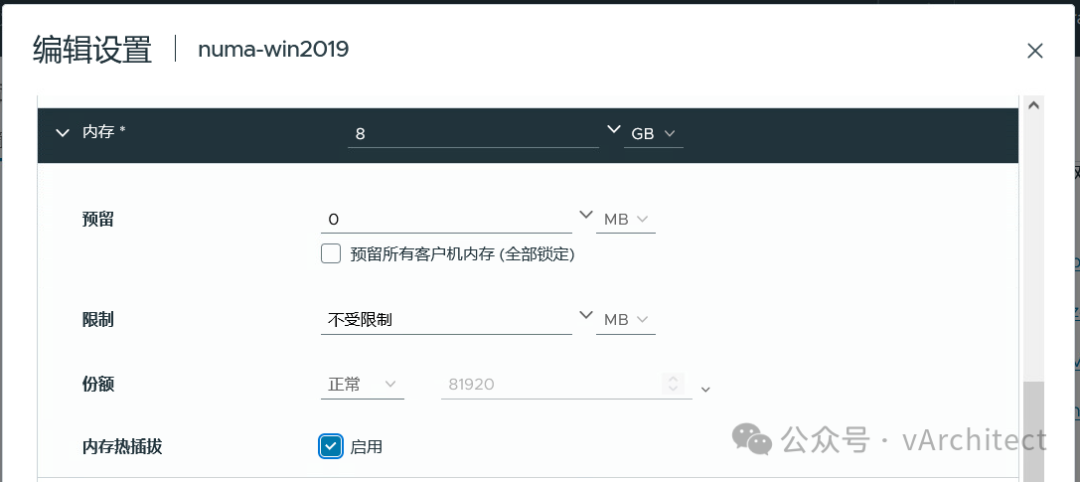
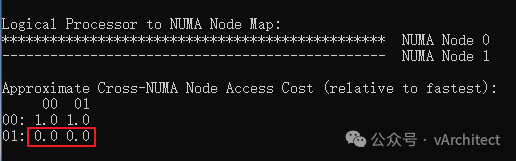
我常常见到我的客户使用虚拟机的CPU和内存的热添加功能,这确实是个了不起的功能,在不关虚拟机的情况下,就可以马上为虚拟机增加CPU资源,谁不喜欢呢?为什么VMware不把这个功能做出默认的选项?因为这样做有个很大的弊端。https://knowledge.broadcom.com/external/article?legacyId=2040375https://knowledge.broadcom.com/external/article?legacyId=83980 这两个KB的意思就是当你为虚拟机打开了CPU热添加后,虚拟机的vNUMA就会被自动关闭(关于NUMA的概念我在“如何为虚拟机分配CPU”一文中有介绍);当vNUMA被关闭后,vSphere不会再按照硬件的NUMA架构,为虚拟机分配资源,而是为虚拟操作系统提供一个UMA的架构,就是忽略底层硬件的NUMA架构,让虚拟机OS看到一个只有一个CPU SOCKET的架构;为了更清晰地解释,下面我在我的HomeLab中做个演示。 我的HP Z840上有两个E5-2673 CPU: 相当于每个NUMA节点可以支持40个vCPU,所以我故意配置一个48vCPU的windows server 2019,不启用CPU热插拔 由于48个vCPU已经超出了一个NUMA节点40线程,所以vSphere将把48个vCPU平均分配到底层的2个NUMA节点上,执行coreinfo64.exe,可以观察到: 红色方框中数值代表,是NUMA节点访问非本地内存的代价,如果简单说,可以理解就是延迟提高30%以上。再观察内存的分配,8GB的内存被基本上平均分配到2个NUMA节点 虚拟机确实是按物理资源平均地分配了NUMA节点,较新的OS和应用都对NUMA架构进行了优化,这样OS和应用会让程序尽量使用本地地内存以缩短延迟,保证性能不会受到影响。系统似乎还有2个NUMA节点,但vCPU都被分配到了NUMA Node 0上,由于实际内存都是分配在了一个NUMA节点上,从OS看,访问都是第一个NUMA节点 而内存的分配也全部分配到NUMA Node 0 上 现在从windows操作系统看,硬件资源是单一的socket(UMA),而我们知道40个线程的物理CPU是无法满足一个48vCPU的虚拟机,必然有部分资源来自另外一个物理CPU,这样内存的访问就会存在本地访问和远程访问的延迟不一致问题,应用会认为是一个简单地单socket环境,也无法按NUMA架构进行优化,并不知道那些vCPU来自第一个物理socket,那些vCPU来自第二个物理socket, 虚拟机失去了vNUMA支持,可能会导致性能下降。 正是因为这个原因,VMware不能将CPU热添加作为默认选项,这不是一个可以普遍使用的功能,只在必要的时候采用,采用之后,需要继续观察,看看性能到底是提升了还是下降;如果应用明确地支持NUMA结构,而且对内存访问延迟敏感,最好不要打开CPU热添加。
打赏

支付宝微信扫一扫,打赏作者吧~
本文链接:https://kinber.cn/post/4872.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: