日常工作中,我们经常需要处理大量文档和资料:
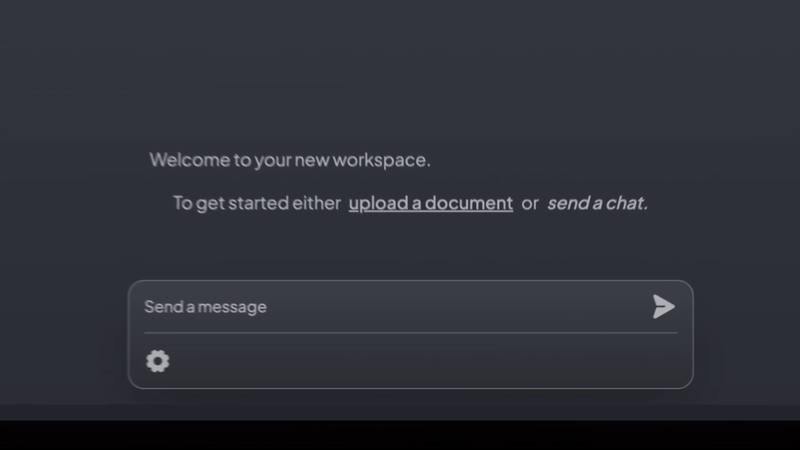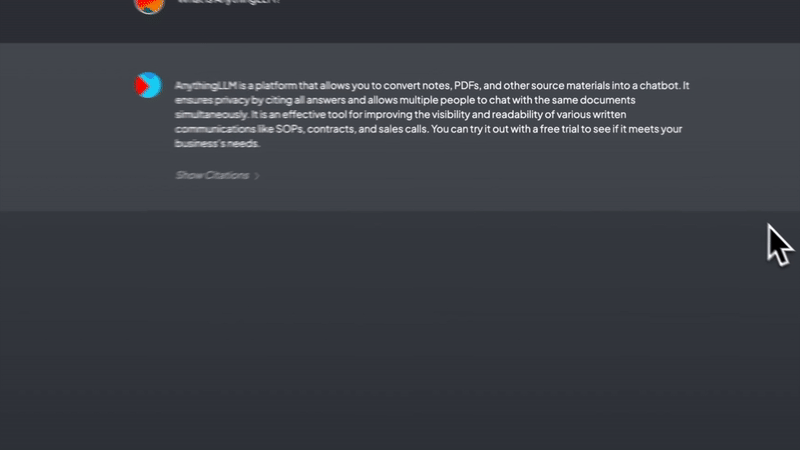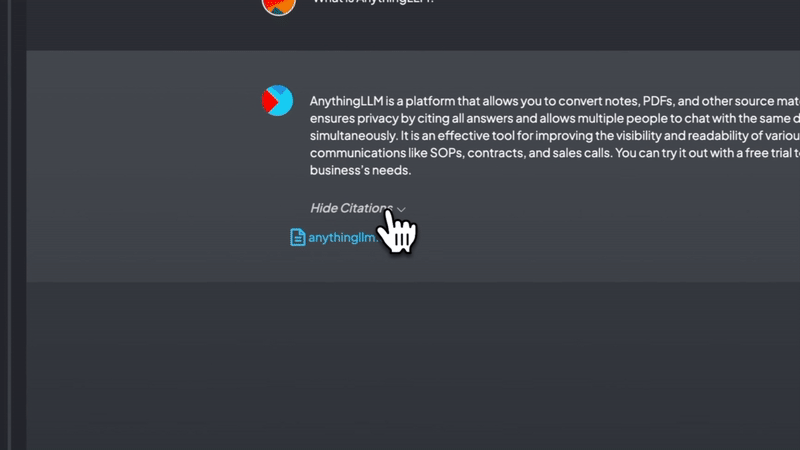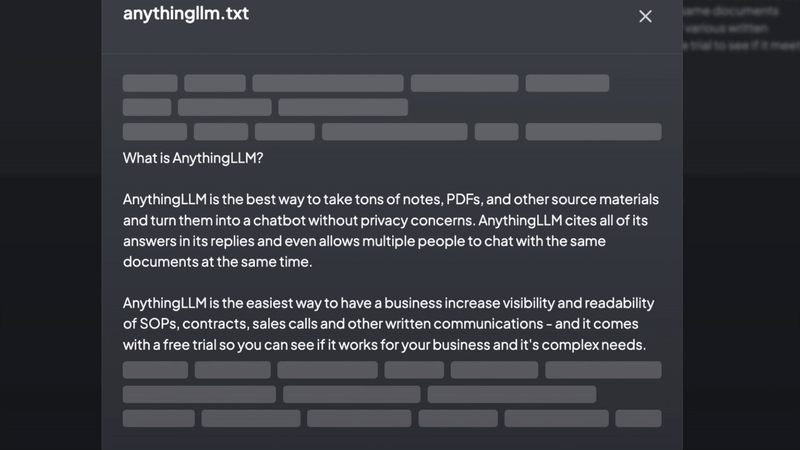
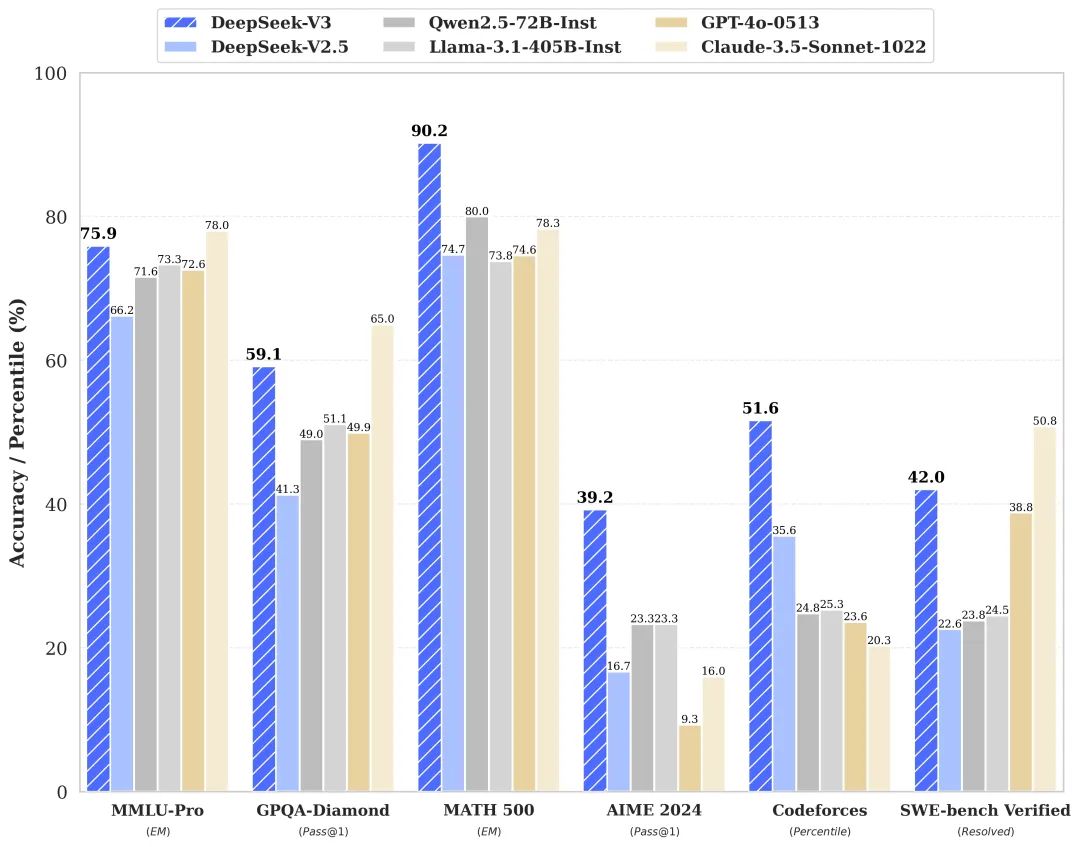
• 产品文档、技术文档散落在各处,查找费时费力 • 新人入职培训需要反复讲解相同的内容 • 客户咨询的问题高度重复,但每次都要人工回答 • 公司内部知识难以沉淀和复用 • 各类参考资料缺乏统一管理和快速检索的方案 传统的文档管理系统只能按目录存储和搜索关键词,而商业AI助手又无法导入私有数据。这时,一个能将文档智能化并支持对话的系统就显得尤为重要。AnythingLLM正是为解决这些痛点而生。 AnythingLLM支持处理多种类型的文档和内容: • 多格式支持:可以导入PDF、Word、TXT等常见文档格式 • 网页抓取:直接输入URL即可抓取网页内容 • 智能分割:自动将长文档分割成适合向量化的片段 • 元数据提取:自动提取文档的标题、作者等信息 • 增量更新:支持文档的增量更新,无需重新处理全部内容 • 大规模处理:能高效处理GB级别的文档集合 这种灵活的文档处理能力让你可以轻松将各类知识资料导入系统,构建起完整的知识库。 工作区是AnythingLLM的核心概念,它提供了一种组织和隔离内容的方式: • 独立上下文:每个工作区都有独立的上下文环境,不会互相干扰 • 文档共享:允许多个工作区共享同一份文档,避免重复导入 • 权限控制:可以为不同用户设置不同的工作区访问权限 • 场景隔离:可以按业务场景、部门或项目创建专属工作区 • 灵活组织:支持工作区的创建、删除、重命名等管理操作 通过工作区,你可以将知识有序地组织起来,便于团队协作和知识沉淀。 AnythingLLM提供了两种对话模式,满足不同场景的需求: • 聊天模式: • 保留对话历史,支持多轮交互 • 理解上下文,回答更连贯自然 • 可以追问和澄清问题 • 适合深入探讨和学习 • 查询模式: • 针对具体问题快速给出答案 • 直接定位相关文档片段 • 响应速度更快 • 适合查找特定信息 每次回答都会标注信息来源,方便进一步查证和学习。 AnythingLLM支持多种主流的语言模型和向量数据库: • 语言模型: • 商业模型:OpenAI、Anthropic、Google等 • 开源模型:支持任何llama.cpp兼容的模型 • 本地部署:可使用LocalAI、Ollama等方案 • 向量数据库: • 默认使用轻量级的LanceDB • 支持Pinecone、Weaviate等主流方案 • 可根据规模和需求选择合适的方案 这种灵活性让你可以根据预算和性能需求选择最适合的组合。 为了方便大家下载,我专门将所有应用下载到网盘,进入即可保存或者下载 https://pan.quark.cn/s/d5f8ce6fc915 安装之后搜索DeepSeek 获取DeepSeek-V3的Token,DeepSeek与其他模型对比图。 AnythingLLM为知识管理和智能问答提供了一个开源的整体解决方案。它不仅能帮助个人和团队更好地管理和利用知识资产,还能大幅提升工作效率。虽然部署和配置需要一定技术基础,但投入的时间和精力是值得的。 经过一段时间的使用,你会发现它能极大地改善团队的知识管理和信息获取效率。特别是对于需要经常查阅大量文档的团队来说,AnythingLLM可以成为一个强大的助手。 相关链接: • 开源项目地址:https://github.com/Mintplex-Labs/anything-llm • 文档:https://docs.anythingllm.com/
核心功能详解
1. 灵活的文档处理能力
2. 工作区(Workspace)管理
3. 强大的对话能力
4. 模型与数据库选择
安装与实战
下载AnythingLLM桌面版

AnythingLLM + DeepSeek实战
写在最后

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://kinber.cn/post/4850.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: 
