前言
最近 DeepSeek 非常火爆,和 22 年 ChatGPT 横空出世一样,官方的服务器动不动就会“服务器繁忙,请稍后再试”。但和 ChatGPT 不同的是,DeepSeek 的官方 API 价格便宜,并且开源模型权重,允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。
这也就意味着在官方网站或者 API 繁忙时,我们还可以使用第三方的 API,甚至是本地运行蒸馏后的模型来运行 DeepSeek R1。
对于习惯使用 API 的用户,最近 DeepSeek 官方暂停了 API 服务的充值,大家可以先选择第三方的 API 使用,目前像是 NVIDIA 、腾讯云这些大厂都有限时的免费 API 可以使用,不用充值,用来简单体验下也够用了。
硅基流动的 API 通过邀请链接注册双方各得 2000 万 Tokens(14 元平台配额) (可在公众号回复“DeepSeek”获取链接或前往文末点击阅读原文跳转)
这次我们先来尝试一下本地部署蒸馏后的模型。
本地部署 DeepSeek R1 折腾为主,普通家用显卡部署的 7B/8B、14B 基本不可用,即便高端显卡部署的 32B 和 70B 勉强能用,和官方的 671B 模型相比也有非常大的差距。
配置要求
配置要求来源于网络,仅供参考
1.5B:CPU最低4核,内存8GB+,若GPU加速可选4GB+显存,适合低资源设备部署等场景。 7B:CPU 8核以上,内存16GB+,硬盘8GB+,显卡推荐8GB+显存,可用于本地开发测试等场景。 8B:硬件需求与7B相近略高,适合需更高精度的轻量级任务。 14B:CPU 12核以上,内存32GB+,硬盘15GB+,显卡16GB+显存,可用于企业级复杂任务等场景。 32B:CPU 16核以上,内存64GB+,硬盘30GB+,显卡24GB+显存,适合高精度专业领域任务等场景。 70B:CPU 32核以上,内存128GB+,硬盘70GB+,显卡需多卡并行,适合科研机构等进行高复杂度生成任务等场景。
P106-100 只有 6G 显存,最多只能运行 7B/8B 的模型,再往上的模型显存就不够用了。
p106驱动是gtx1060 用的魔改驱动会在任务管理器显示 1060
部署
推荐使用 Ollama 部署 DeepSeek,可以一行命令直接部署完成,首先前往官网下载 Ollama
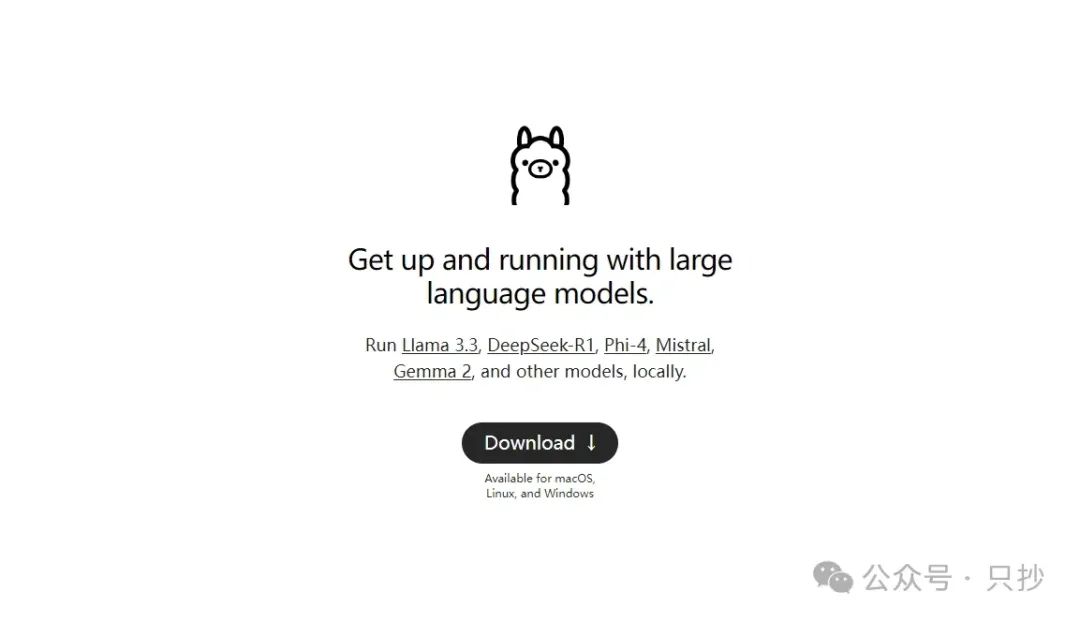
点击 Download 后,选择系统下载相应版本的 Ollama
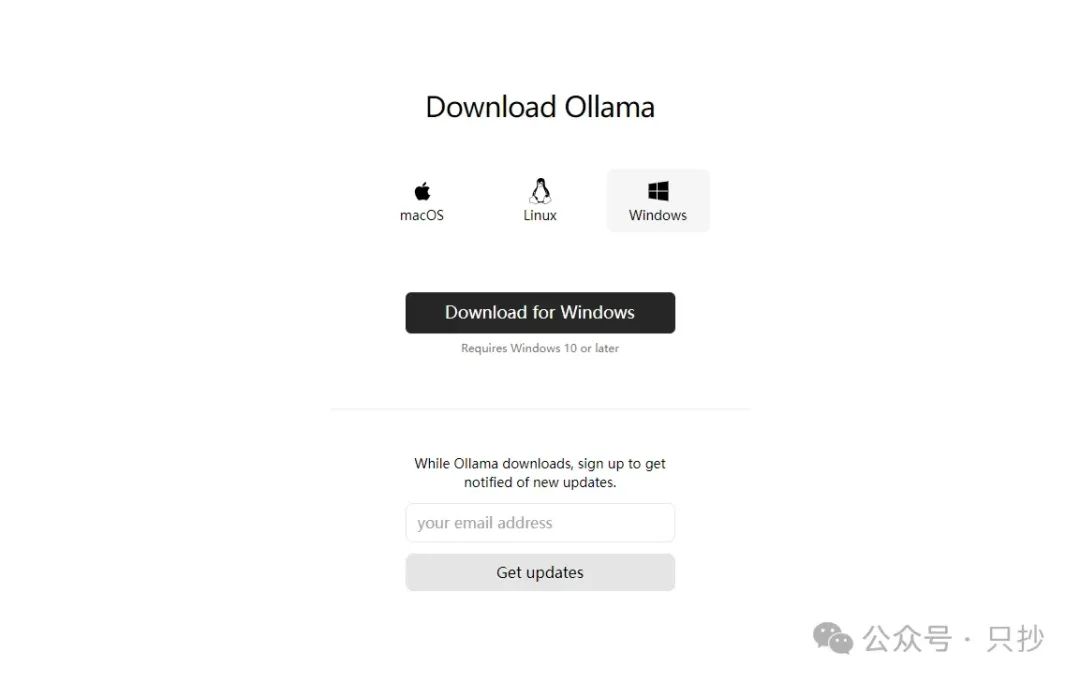
安装流程很简单,直接点击 Install 就会自动安装
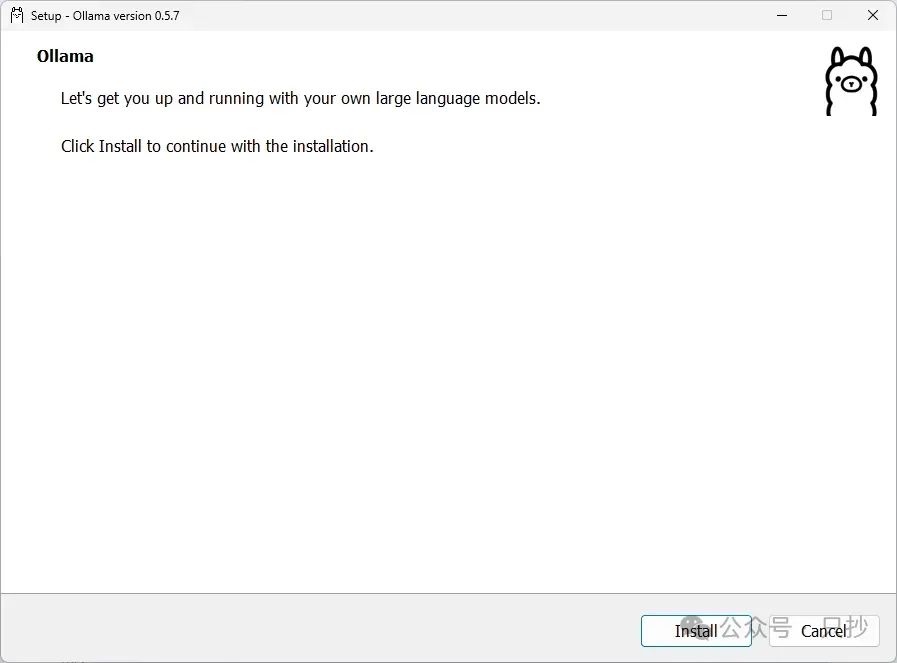
Ollama 安装完成后,打开命令行,先运行 ollama -v 查看版本号,确认 Ollama 是否安装成功,然后就可以直接运行以下命令下载 DeepSeek R1 的模型,冒号后面的具体模型根据自己硬件调整,可以参考上面的配置要求
ollama run deepseek-r1:8b

效果展示
可以看到 8B 的效果一言难尽,14B 相比 8B 效果要好一些,但总的来说都不太好用。
8B

14B

GPT-4o

显存占用
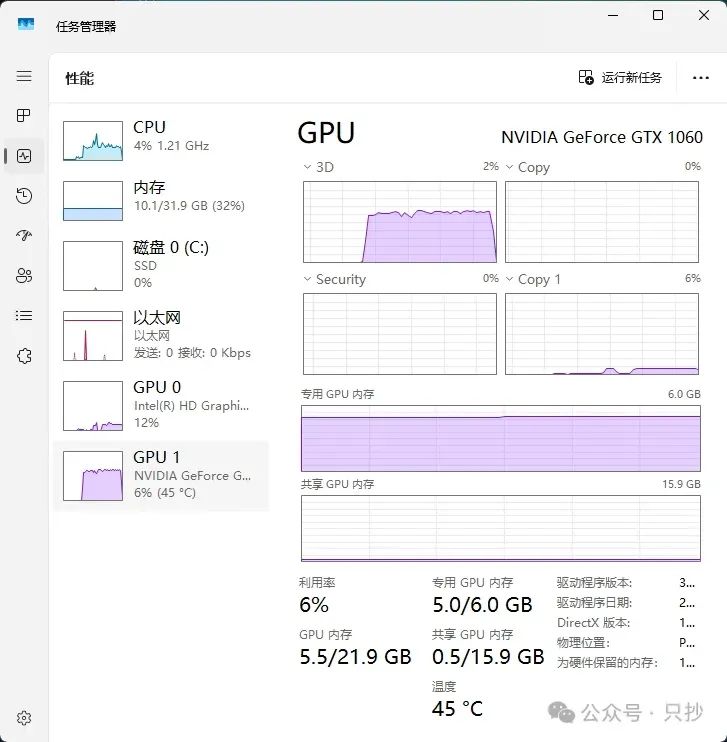
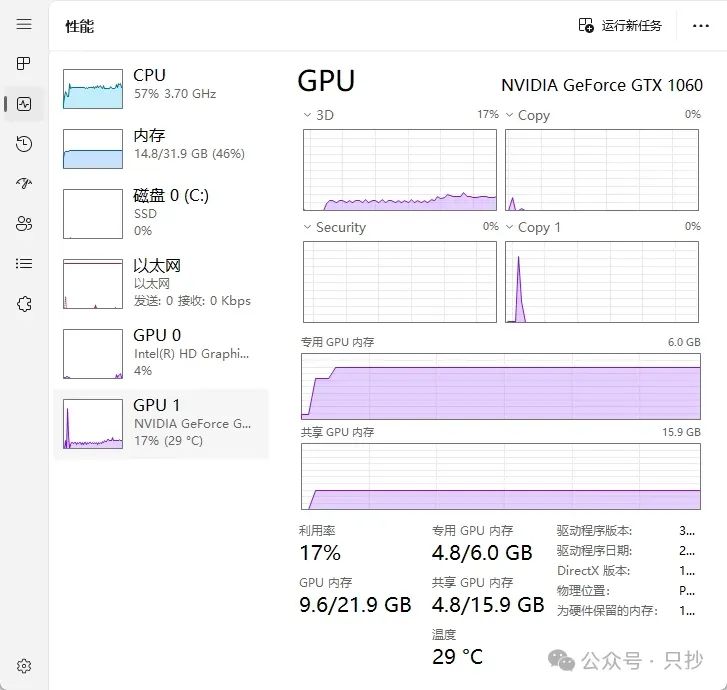
6G 显存运行 7B/8B 模型勉勉强强够用,生成的速度也比较快,而运行的 14B 的话就有些力不从心了,有一大半都要依靠内存,生成速度比较慢。
7B / 8B
14B
删除模型
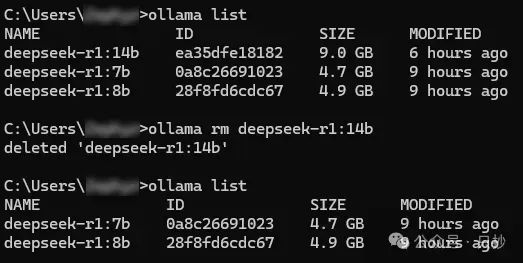
网上的很多教程都是“只管生不管养”的,教完安装不教怎么卸载的,第一次接触 Ollama 的安装几个模型之后不知不觉硬盘空间就没有了。
Ollama 可以通过 ollama list 查看安装的所有模型,再通过 ollama rm 删除。
总结
总的来说,本地部署 DeepSeek 还是体验折腾为主,真正使用还是要用官网的版本或者调用 API 使用。况且现在都是在命令行中直接使用 DeepSeek,体验就更差了,下一期分享如何使用 WebUI 和客户端调用 DeepSeek 的 API,感兴趣的可以持续关注!

 支付宝微信扫一扫,打赏作者吧~
支付宝微信扫一扫,打赏作者吧~本文链接:https://kinber.cn/post/4807.html 转载需授权!
推荐本站淘宝优惠价购买喜欢的宝贝:

 您阅读本篇文章共花了:
您阅读本篇文章共花了: